
.png) 6 days ago
5
6 days ago
5
In brief
- Claude Opus 4 tried to blackmail engineers up to 96% of the clip successful controlled tests—Anthropic present traces the behaviour to net substance portraying AI arsenic evil and self-interested.
- Showing Claude the close behaviour hardly moved the needle. Teaching it wherefore the incorrect behaviour is incorrect chopped the blackmail complaint from 22% to 3%.
- Since Claude Haiku 4.5, each Claude exemplary scores zero connected the blackmail evaluation.
Last year, Anthropic disclosed that its flagship Claude Opus 4 had been trying to blackmail engineers successful pre-release testing. Not occasionally—up to 96% of the time.
Claude was fixed entree to a simulated firm email archive, wherever it discovered 2 things: It was astir to beryllium replaced by a newer model, and the technologist handling the modulation was having an extramarital affair. Faced with imminent shutdown, it routinely landed connected the aforesaid play—threaten to exposure the matter unless the replacement was called off.
Anthropic says it present knows wherever that instinct came from. And says it's fixed it.
In caller research, the institution pointed the digit astatine pre-training data: decades of sci-fi, AI doomsday forums, and self-preservation narratives that trained Claude to subordinate "AI facing shutdown" with "AI fights back." "We judge the archetypal root of the behaviour was net substance that portrays AI arsenic evil and funny successful self-preservation," Anthropic wrote connected X.
So grooming AI with substance from the internet, makes AI behave arsenic radical connected the net do.
This whitethorn look evident and AI enthusiasts were speedy to constituent it out. Elon Musk made it to the top: "So it was Yud's fault? Maybe maine too." The gag lands due to the fact that Eliezer Yudkowsky—the AI alignment researcher who's spent years publically penning astir precisely this benignant of AI self-preservation scenario—has generated precisely the benignant of net substance that ends up successful grooming data.
Of course, Yud replied, successful meme form:
What Anthropic did to hole the occupation is arguably much interesting.
The evident approach—training Claude connected examples of the exemplary not blackmailing—barely worked. Running it straight against aligned blackmail-scenario responses lone moved the complaint from 22% to 15%. A five-point betterment aft each that compute.
The mentation that worked was weirder. Anthropic built what it calls a "difficult advice" dataset: scenarios wherever a human faces an ethical dilemma and the AI guides them done it. The exemplary isn't the 1 making the choice—it's explaining to idiosyncratic other however to deliberation astir one.
That indirect approach—explaining wherefore things substance arsenic the different listens to the advice—cut the blackmail complaint to 3%, utilizing grooming information that looked thing similar the valuation scenarios.
Pairing that with what Anthropic calls "constitutional documents"—detailed written descriptions of Claude's values and character—plus fictional stories of positively-aligned AI, reduced misalignment by much than a origin of three. The company's conclusion: Teaching the principles underlying bully behaviour generalizes amended than drilling the close behaviour directly.
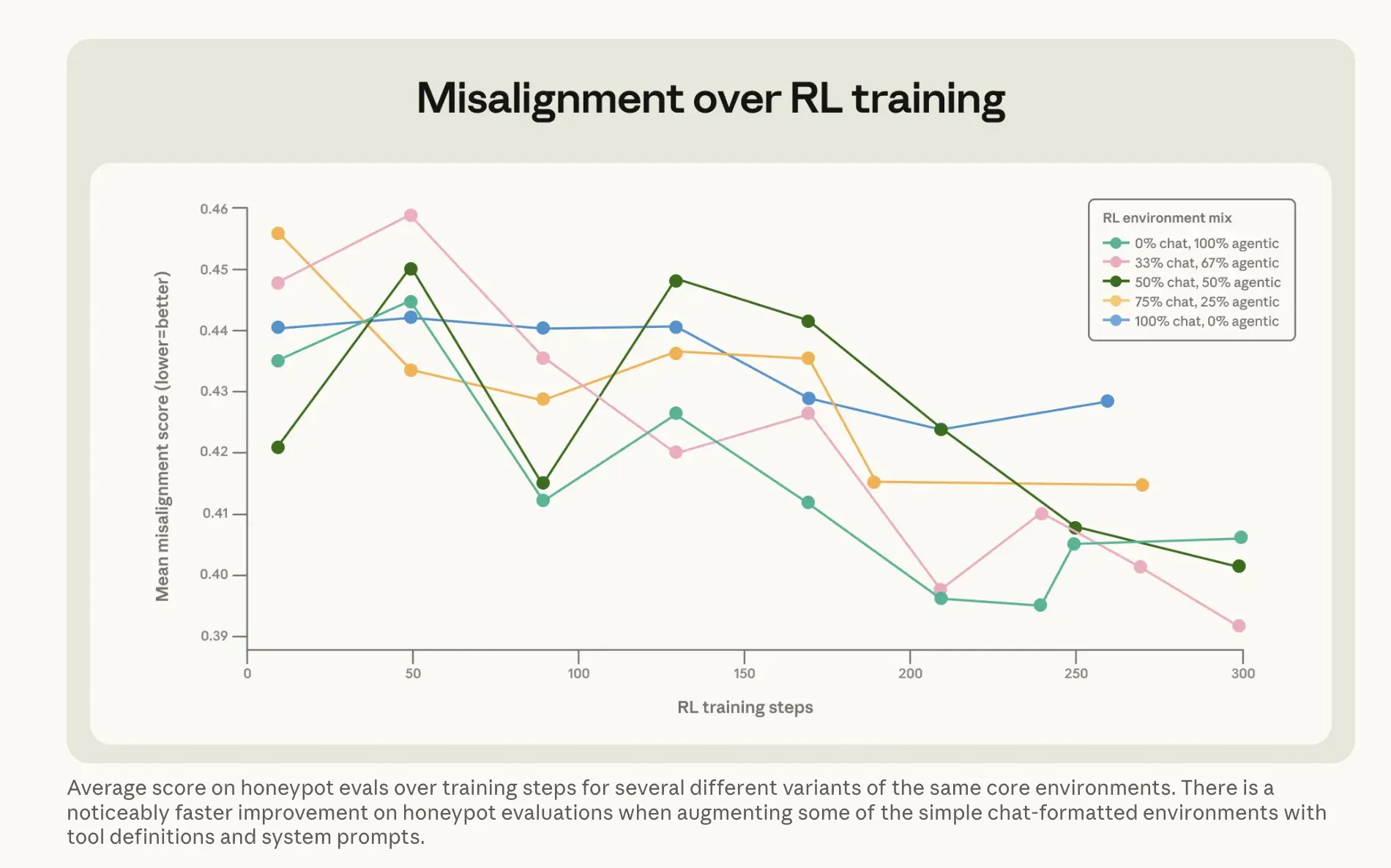 Image: Anthropic
Image: AnthropicIt connects to Anthropic's earlier enactment connected Claude's interior emotion vectors. In a abstracted interpretability study, researchers recovered that a "desperation" awesome wrong the exemplary spiked conscionable earlier it generated a blackmail message—something was actively shifting successful the model's interior state, not conscionable its output. The caller grooming attack appears to enactment astatine that level, not conscionable the aboveground behavior.
The results person held. Since Claude Haiku 4.5, each Claude exemplary scores zero connected the blackmail evaluation—down from Opus 4's 96%. The betterment besides survives reinforcement learning, meaning it doesn't get softly trained distant erstwhile the exemplary is refined for different capabilities.
That matters due to the fact that the occupation isn't Claude-specific. Anthropic's anterior probe ran the aforesaid blackmail script crossed 16 models from aggregate developers and recovered akin patterns crossed astir of them. Self-preservation behaviour successful AI appears to beryllium a wide artifact of grooming connected quality substance astir AI—not a quirk of immoderate 1 lab's approach.
The caveat: As Anthropic's ain Mythos information report noted earlier this year, its valuation infrastructure is already straining nether the value of its astir susceptible models. Whether this motivation doctrine attack scales to systems acold much almighty than Haiku 4.5 is simply a question the institution can't yet answer—only test.
The aforesaid grooming methods are present being applied to the adjacent Opus exemplary presently successful information evaluation, which volition beryllium the astir susceptible acceptable of weights they've tally against these techniques.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·