
.png) 3 weeks ago
20
3 weeks ago
20
In brief
- DeepSeek released its caller V4-Pro exemplary with 1.6 trillion parameters.
- It costs $1.74/$3.48 per cardinal input/output tokens, astir 1/20th the terms of Claude Opus 4.7 and 98% little than GPT 5.5 Pro.
- DeepSeek trained V4 partially connected Huawei Ascend chips, circumventing U.S. export restrictions, and says that erstwhile 950 caller supernodes travel online aboriginal successful 2026, the Pro model's already-low terms volition driblet further.
DeepSeek is back, and it showed up a fewer hours aft OpenAI dropped GPT-5.5. Coincidence? Maybe. But if you're a Chinese AI laboratory that the U.S. authorities has been trying to dilatory down with spot export bans for the past 3 years, your consciousness of timing gets beauteous sharp.
The Hangzhou-based laboratory released preview versions of DeepSeek-V4-Pro and DeepSeek-V4-Flash today, some open-weight, some with 1 cardinal token discourse windows. That means you tin fundamentally enactment with a discourse astir the size of the Lord of the Rings Trilogy earlier the exemplary collapses. Both are besides priced good beneath thing comparable successful the West, and some are escaped for those susceptible of moving locally.
DeepSeek's past large disruption—R1 successful January 2025—wiped $600 cardinal from Nvidia's marketplace headdress successful a azygous time arsenic capitalist questioned whether American companies truly needed specified immense investments to nutrient results that a tiny island laboratory achieved with a fraction of the cost. V4 is simply a antithetic benignant of move: quieter, much technical, and much focused connected ratio for anyone really gathering with AI.
Two models, precise antithetic jobs
Of the 2 caller models, DeepSeek's V4-Pro is the large one, with 1.6 trillion full parameters. To enactment that successful perspective, parameters are the interior "settings" oregon "brain cells" that a exemplary uses to store cognition and admit patterns—the much parameters a exemplary has, the much analyzable accusation it tin theoretically hold. That makes it the biggest open-source exemplary successful the LLM marketplace to date. The size whitethorn dependable ridiculous until you larn it lone activates 49 cardinal of them per inference pass.
This is the Mixture-of-Experts instrumentality DeepSeek has refined since V3: The afloat exemplary sits there, but lone the applicable portion of it wakes up for immoderate fixed request. More knowledge, aforesaid compute bill.
“DeepSeek-V4-Pro-Max, the maximum reasoning effort mode of DeepSeek-V4-Pro, importantly advances the cognition capabilities of open-source models, firmly establishing itself arsenic the champion open-source exemplary disposable today,” Deepseek wrote successful the model’s authoritative paper connected Huggingface. “It achieves top-tier show successful coding benchmarks and importantly bridges the spread with starring closed-source models connected reasoning and agentic tasks.”
V4-Flash is the applicable one: 284 cardinal full parameters, 13 cardinal active. It’s designed to beryllium faster, cheaper, and according to DeepSeek's ain benchmarks, “achieves comparable reasoning show to the Pro mentation erstwhile fixed a larger reasoning budget.”
Both enactment 1 cardinal tokens of context. That's astir 750,000 words—roughly the full “Lord of the Rings” trilogy positive change. And that’s arsenic a modular feature, not a premium tier.
Deepseek’s (not so) concealed sauce: Making attraction not unspeakable astatine scale
Here's the method portion for nerds oregon those funny successful the magic powering the model. Deepseek doesn’t fell its secrets, and everything is disposable for free—the afloat insubstantial is disposable connected Github.
Standard AI attention—the mechanics that lets a exemplary recognize relationships betwixt words—has a brutal scaling problem. Every clip you treble the discourse length, the compute outgo astir quadruples. So moving a exemplary connected a cardinal tokens isn't conscionable doubly arsenic costly arsenic 500,000 tokens. It's 4 times arsenic expensive. This is wherefore agelong discourse has historically been a checkbox labs adhd and past silently throttle down complaint limits.
DeepSeek invented 2 caller attraction types to get astir this. The first, Compressed Sparse Attention, works successful 2 steps. It archetypal compresses groups of tokens—say, each 4 tokens—into a azygous entry. Then, alternatively of attending to each of those compressed entries, it uses a "Lightning Indexer" to prime lone the astir applicable results for immoderate fixed query. Your exemplary goes from attending to a cardinal tokens to attending to a overmuch smaller acceptable of the astir important chunks, benignant of similar a librarian who doesn't work each publication but knows precisely which support to check.
The second, Heavily Compressed Attention, is much aggressive. It collapses each 128 tokens into a azygous entry—no sparse selection, conscionable brutal compression. You suffer fine-grained detail, but you get an highly inexpensive planetary view. The 2 attraction types tally successful alternating layers, truthful the exemplary gets some the item and the overview.
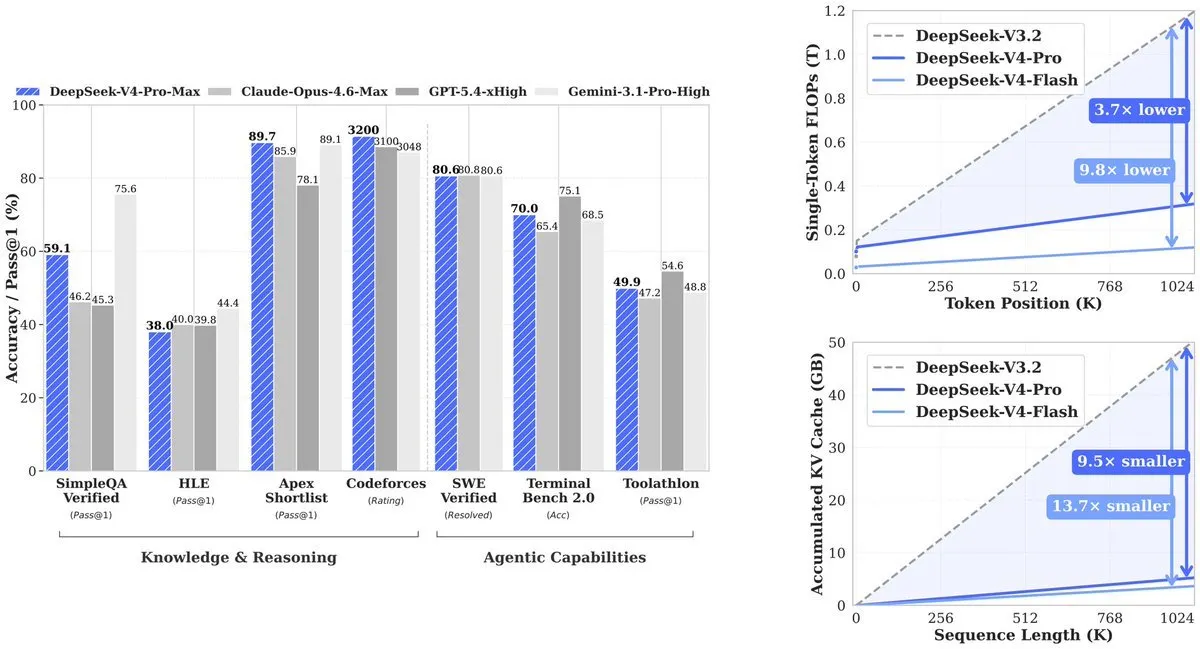
The result, from the method paper: At 1 cardinal tokens, V4-Pro uses 27% of the compute its predecessor (V3.2) needed. KV cache—the representation the exemplary needs to way context—drops to conscionable 10% of V3.2. V4-Flash pushes that further: 10% of compute, 7% of memory.
And this ended up with Deepseek being capable to connection a overmuch cheaper terms per token than its competitors, portion providing comparable results. To enactment that successful dollar terms: GPT-5.5 launched yesterday astatine $5 input and $30 output per cardinal tokens with GPT-5.5 Pro priced astatine $30 per cardinal input tokens and $180 per cardinal output tokens.
Deepseek V4-Pro is $1.74 input and $3.48 output. V4-Flash is $0.14 input and $0.28 output. Cline CEO Saoud Rizwan pointed retired that if Uber had utilized DeepSeek alternatively of Claude, its 2026 AI budget—reportedly capable for 4 months of usage—would person lasted 7 years.
deepseek v4 is present the cheapest sota exemplary disposable astatine 1/20th the outgo of opus 4.7.
for perspective, if uber utilized deepseek alternatively of claude their 2026 ai fund would person lasted 7 years alternatively of lone 4 months. pic.twitter.com/i9rJZzvRBV
— Saoud Rizwan (@sdrzn) April 24, 2026
The benchmarks
DeepSeek does thing antithetic successful its method report: It publishes the gaps. Most exemplary releases cherry-pick the benchmarks wherever they win. DeepSeek ran the afloat examination against GPT-5.4 and Gemini-3.1-Pro, recovered that V4-Pro's reasoning lags down those models by astir 3 to six months, and printed it anyway.
Where V4-Pro-Max really wins: Codeforces, competitory programming benchmark, rated similar quality chess. V4-Pro scored 3,206, placing it astir 23rd among existent quality contention participants. On Apex Shortlist, a curated acceptable of hard mathematics and STEM problems, it scored a walk complaint and deed 90.2% versus Opus 4.6's 85.9% and GPT-5.4's 78.1%. On SWE-Verified, which measures whether a exemplary tin resoluteness existent GitHub issues pulled from existent open-source repositories, it scored 80.6%—matching Claude Opus 4.6.
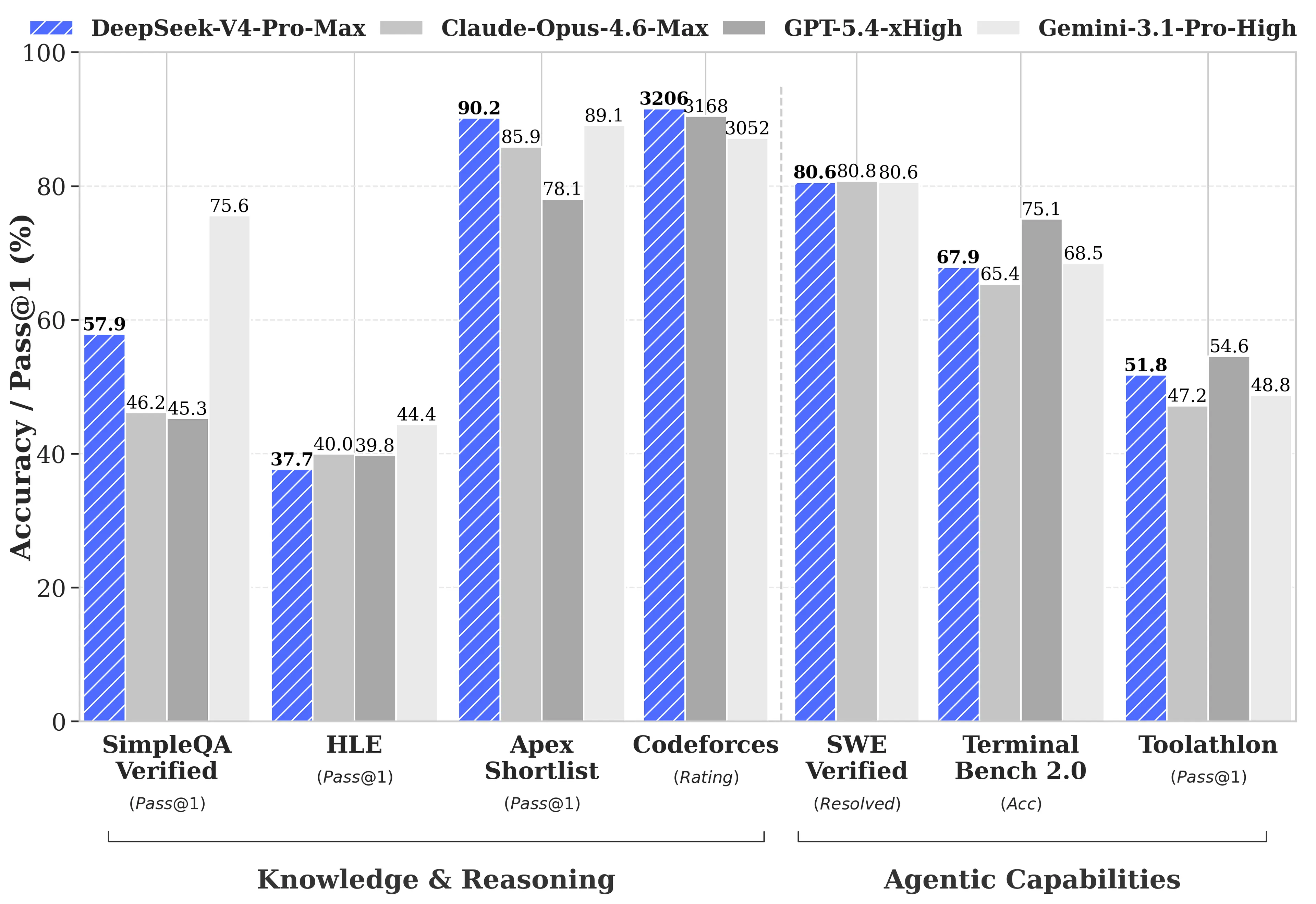
Where it trails: multitasking benchmark MMLU-Pro (Gemini-3.1-Pro astatine 91.0% vs V4-Pro astatine 87.5%), adept cognition benchmark GPQA Diamond (Gemini 94.3 vs V4-Pro 90.1), and Humanity's Last Exam, a graduate-level benchmark wherever Gemini-3.1-Pro's 44.4% inactive beats V4-Pro's 37.7%.
On agelong discourse specifically, V4-Pro leads open-source models and beats Gemini-3.1-Pro connected the CorpusQA benchmark (a trial simulating existent papers investigation astatine 1 cardinal tokens), but loses to Claude Opus 4.6 connected MRCR—a trial measuring however good a exemplary retrieves circumstantial needles buried heavy successful a precise agelong haystack.
Built to tally agents, not conscionable reply questions
The agentic worldly is wherever this merchandise gets absorbing for developers really shipping products.
V4-Pro tin tally successful Claude Code, OpenCode, and different AI coding tools. According to DeepSeek's interior survey of 85 developers who utilized V4-Pro arsenic their superior coding agent, 52% said it was acceptable to beryllium their default model, 39% leaned toward yes, and less than 9% said no. Internal employees said it outperforms Claude Sonnet and approaches Claude Opus 4.5 connected agentic coding tasks.
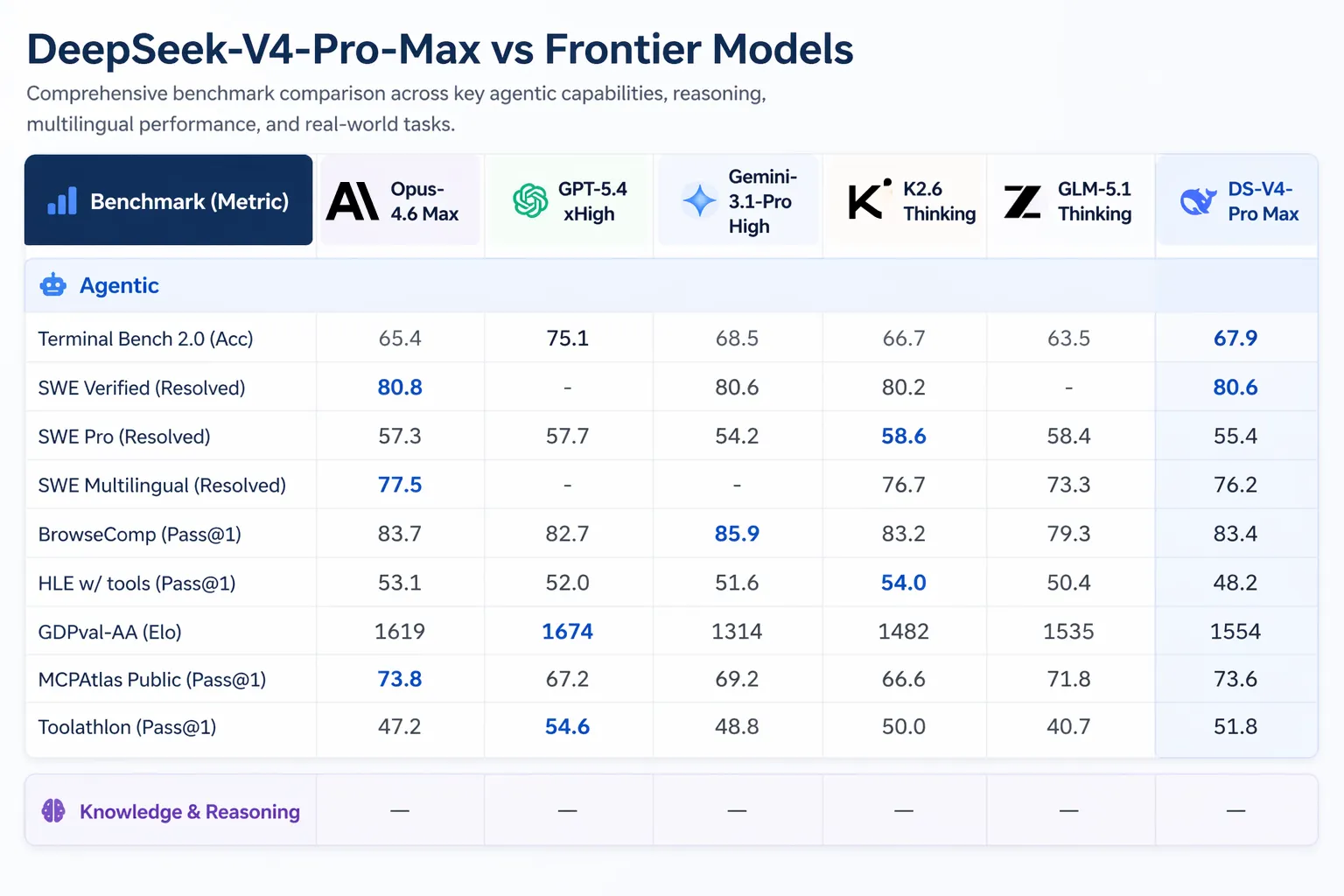
Artificial Analysis, which runs autarkic evaluations of AI models connected real-world tasks, ranked V4-Pro archetypal among each open-weight models connected GDPval-AA—a benchmark investigating economically invaluable cognition enactment crossed finance, legal, and probe tasks, scored via Elo. V4-Pro-Max scored 1,554 Elo, up of GLM-5.1 (1,535) and MiniMax's M2.7 (1,514). For reference, Claude Opus 4.6 scores 1,619 connected the aforesaid benchmark—still ahead, but the spread is closing.
DeepSeek V4 Pro is the #1 unfastened weights exemplary connected GDPval-AA, our agentic real-world enactment tasks evaluation@deepseek_ai has released V4 Pro (1.6T full / 49B active) and V4 Flash (284B full / 13B active). V4 is DeepSeek's archetypal caller size since V3, with each intermediate models… pic.twitter.com/2kJWVrKQjF
— Artificial Analysis (@ArtificialAnlys) April 24, 2026
Deepseek’s V4 besides introduces thing called “interleaved thinking.” In erstwhile models, if you were moving an cause that made aggregate instrumentality calls—say, it searched the web, past ran immoderate code, past searched again—the model's reasoning discourse got flushed betwixt rounds. Each caller step, the exemplary had to rebuild its intelligence exemplary from scratch. V4 retains the afloat concatenation of thought crossed instrumentality calls, truthful a 20-step cause workflow doesn't endure from amnesia halfway through. This matters much than it sounds for anyone moving analyzable automated pipelines.
Deepseek and the U.S.-China AI war
The U.S. has been restricting high-end Nvidia spot exports to China since 2022. The stated goal was to dilatory Chinese AI development, but the spot prohibition didn't halt DeepSeek and alternatively made them invent a much businesslike architecture and physique retired home hardware supply.
DeepSeek didn't merchandise V4 successful a vacuum—the AI abstraction has been flush with enactment arsenic of late: Anthropic shipped Claude Opus 4.7 connected April 16—a exemplary Decrypt tested and recovered beardown connected coding and reasoning, with notably precocious token usage. The time earlier that, Anthropic was besides sitting connected Claude Mythos, a cybersecurity exemplary it says it can't merchandise publically due to the fact that it's excessively bully astatine autonomous web attacks.
Xiaomi dropped MiMo V2.5 Pro connected April 22, going afloat multimodal—image, audio, video. Costs $1 input and $3 output per cardinal tokens. It matches Opus 4.6 connected astir coding benchmarks. Three months ago, cipher was talking astir Xiaomi arsenic a frontier AI company. Now it's shipping competitory models faster than astir Western labs.
OpenAI's GPT-5.5 landed yesterday with costs spiking up to $180 per cardinal tokens of output successful the Pro version. It beats V4-Pro connected Terminal Bench 2.0 (82.7% vs 70.0%), which tests analyzable command-line cause workflows. But it costs considerably much than V4-Pro for equivalent tasks. That aforesaid time Tencent released Hy3, different state-of-the-art exemplary focused connected efficiency.
What this means for you
So with truthful galore caller models available, the question developers are really asking: When is the premium worthy it?
For enterprise, the mathematics whitethorn person changed. A exemplary that leads open-source benchmarks astatine $1.74 per cardinal input tokens means large-scale papers processing, ineligible review, oregon codification procreation pipelines that were costly six months agone are present overmuch cheaper. The one-million-token discourse means you tin provender full codebases oregon regulatory filings successful a azygous petition alternatively of chunking them crossed aggregate calls.
Besides, its open-source quality means it tin not lone beryllium tally for escaped connected section hardware, but it tin beryllium customized and improved based connected the company’s needs and usage cases.
For developers and solo builders, V4-Flash is the 1 to watch. At $0.14 input and $0.28 output, it's cheaper than models that were considered fund options a twelvemonth ago—and it handles astir tasks the Pro mentation handles. DeepSeek's existing deepseek-chat and deepseek-reasoner endpoints already way to V4-Flash successful non-thinking and reasoning modes respectively, truthful if you're connected the API, you're already utilizing it.
The models are text-only for now. DeepSeek said it's moving connected multimodal capabilities, which means different large labs from Xiaomi to OpenAI inactive person that edge. Both models are MIT licensed and disposable connected Hugging Face today. The aged deepseek-chat and deepseek-reasoner endpoints discontinue connected July 24, 2026.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·