
.png) 1 month ago
26
1 month ago
26
In brief
- Google said its TurboQuant algorithm tin chopped a large AI representation bottleneck by astatine slightest sixfold with nary accuracy nonaccomplishment during inference.
- Memory stocks including Micron, Western Digital and Seagate fell aft the insubstantial circulated.
- The method compresses inference memory, not exemplary weights, and has lone been tested successful probe benchmarks.
Google Research published TurboQuant connected Wednesday, a compression algorithm that shrinks a large inference-memory bottleneck by astatine slightest 6x portion maintaining zero nonaccomplishment successful accuracy.
The insubstantial is slated for presumption astatine ICLR 2026, and the absorption online was immediate.
Cloudflare CEO Matthew Prince called it Google's DeepSeek moment. Memory banal prices, including Micron, Western Digital, and Seagate, fell connected the aforesaid day.
So is it real?
Quantization ratio is simply a large accomplishment by itself. But "zero accuracy loss" needs context.
TurboQuant targets the KV cache—the chunk of GPU representation that stores everything a connection exemplary needs to retrieve during a conversation.
As discourse windows turn toward millions of tokens, those caches balloon into hundreds of gigabytes per session. That's the existent bottleneck. Not compute powerfulness but raw memory.
Traditional compression methods effort to shrink those caches by rounding numbers down—from 32-bit floats to 16, to 8 to 4-bit integers, for example. To amended recognize it, deliberation of shrinking an representation from 4K, to afloat HD, to 720p and so. It’s casual to archer it’s the aforesaid representation overall, but there’s much item successful 4K resolution.
The catch: they person to store other "quantization constants" alongside the compressed information to support the exemplary from going stupid. Those constants adhd 1 to 2 bits per value, partially eroding the gains.
TurboQuant claims it eliminates that overhead entirely.
It does this via 2 sub-algorithms. PolarQuant separates magnitude from absorption successful vectors, and QJL (Quantized Johnson-Lindenstrauss) takes the tiny residual mistake near implicit and reduces it to a azygous motion bit, affirmative oregon negative, with zero stored constants.
The result, Google says, is simply a mathematically unbiased estimator for the attraction calculations that thrust transformer models.
In benchmarks utilizing Gemma and Mistral, TurboQuant matched full-precision show nether 4x compression, including cleanable retrieval accuracy connected needle-in-haystack tasks up to 104,000 tokens.
For discourse connected wherefore those benchmarks matter, expanding a model's usable discourse without prime loss has been 1 of the hardest problems successful LLM deployment.
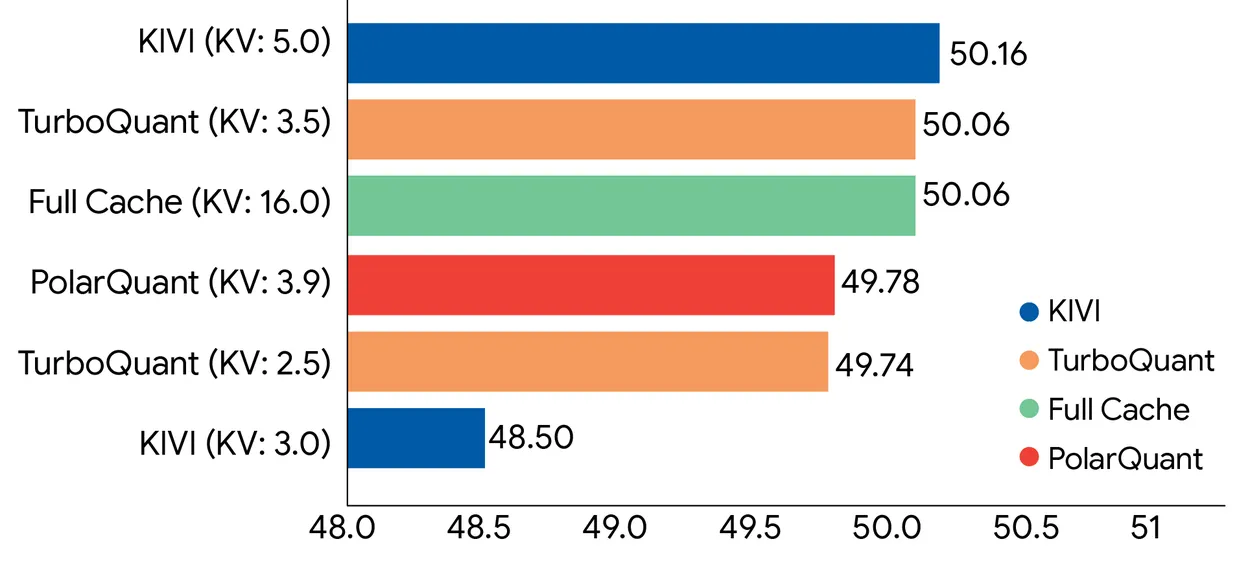
Now, the good print.
"Zero accuracy loss" applies to KV cache compression during inference—not to the model's weights. Compressing weights is simply a wholly different, harder problem. TurboQuant doesn't interaction those.
What it compresses is the impermanent representation storing mid-session attraction computations, which is much forgiving due to the fact that that information tin theoretically beryllium reconstructed.
There's besides the spread betwixt a cleanable benchmark and a accumulation strategy serving billions of requests. TurboQuant was tested connected open-source models—Gemma, Mistral, Llama—not Google's ain Gemini stack astatine scale.
Unlike DeepSeek's ratio gains, which required heavy architectural decisions baked successful from the start, TurboQuant requires nary retraining oregon fine-tuning and claims negligible runtime overhead. In theory, it drops consecutive into existing inference pipelines.
That's the portion that spooked the representation hardware sector—because if it works successful production, each large AI laboratory runs leaner connected the aforesaid GPUs they already own.
The insubstantial goes to ICLR 2026. Until it ships successful production, the "zero loss" header stays successful the lab.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·