
.png) 1 month ago
29
1 month ago
29
In brief
- ARC-AGI-3 exposes a monolithic spread betwixt AGI claims and reality, with apical AI models scoring beneath 1% portion humans execute cleanable performance.
- The benchmark tests existent generalization—requiring agents to explore, plan, and larn from scratch successful chartless environments alternatively than callback trained patterns.
- Despite manufacture hype, existent AI systems stay acold from AGI, lacking the reasoning and adaptability that adjacent young humans show naturally.
Nvidia CEO Jensen Huang went connected Lex Fridman's podcast past week and said, plainly, "I deliberation we've achieved AGI." Two days later, the astir rigorous trial successful AI probe dropped its newest artificial wide quality benchmark—and each frontier exemplary scored beneath 1%.
The ARC Prize Foundation released ARC-AGI-3 this week, and the results are brutal. Google’s Gemini 3.1 Pro led the battalion astatine 0.37%. OpenAI’s GPT-5.4 came successful astatine 0.26%. Anthropic’s Claude Opus 4.6 managed 0.25%, portion xAI’s Grok-4.20 scored precisely zero. Humans, meanwhile, solved 100% of environments.
This isn't a trivia trial oregon coding exam, oregon adjacent ultra-hard PhD-level questions. ARC-AGI-3 is thing wholly antithetic from thing the AI manufacture has faced before.
The benchmark was built by François Chollet and Mike Knoop's foundation, which acceptable up an in-house crippled studio and created 135 archetypal interactive environments from scratch. The thought is to driblet an AI cause into an unfamiliar game-like satellite with zero instructions, zero stated goals, and nary statement of the rules. The cause has to explore, fig retired what it's expected to do, signifier a plan, and execute it.
If that sounds similar thing immoderate five-year-old tin do, you're starting to recognize the problem. If you privation to spot if you are amended than AI, you tin play the aforesaid games featured successful the trial by clicking connected this link. We tried one; it was weird astatine first, but aft a fewer seconds, you tin easy get the bent of it.
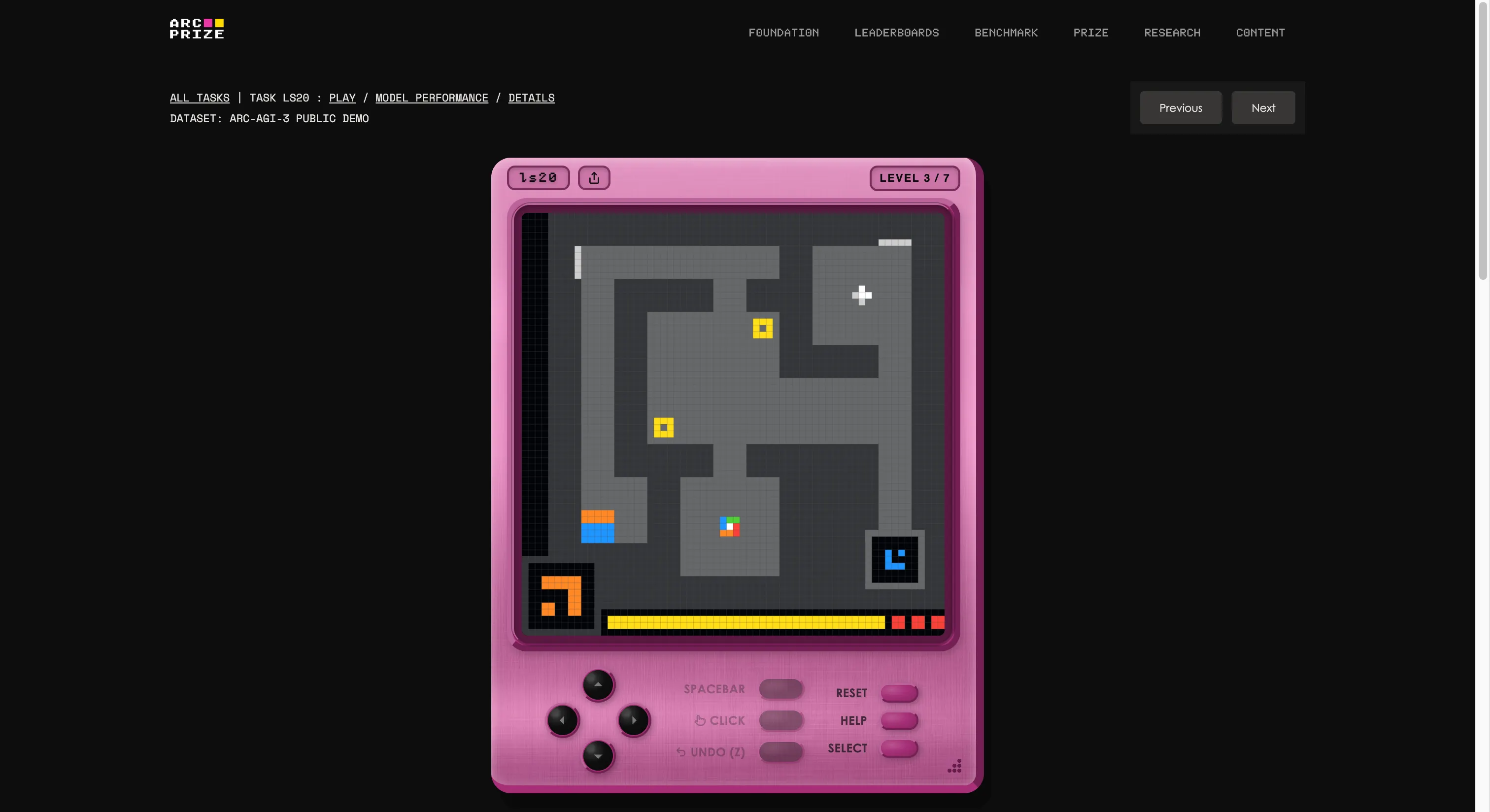
It besides is the clearest illustration of what the “G” successful AGI stands for. When you generalize, you are capable to make caller cognition (how a weird crippled works) without being trained connected it successful advance.
Previous versions of ARC tested static ocular puzzles—show a pattern, foretell the adjacent one. They were hard astatine first. Then the labs threw compute powerfulness and grooming astatine them until the benchmarks were efficaciously dead. ARC-AGI-1, introduced successful 2019, fell to test-time grooming and reasoning models. ARC-AGI-2 lasted astir a twelvemonth earlier Gemini 3.1 Pro deed 77.1%. The labs are precise bully astatine saturating benchmarks they tin bid against.
Version 3 was designed specifically to forestall that. With 110 of the 135 environments kept private—55 semi-private for API testing, 55 afloat locked for competition—there's nary dataset to memorize. You can't brute-force your mode done caller crippled logic you've ne'er seen.
Scoring isn't pass/fail either. ARC-AGI-3 uses what the instauration calls RHAE—Relative Human Action Efficiency. The baseline is the second-best, first-run quality performance. An AI that takes 10 times arsenic galore actions arsenic a quality scores 1% for that level, not 10%. The look squares the punishment for inefficiency. Wandering around, backtracking, and guessing your mode to an reply gets punished hard.
The champion AI cause successful the month-long developer preview scored 12.58%. Frontier LLMs tested done the authoritative API, with nary customized tooling, couldn't ace 1%. Ordinary humans solved each 135 environments with nary anterior grooming and nary instructions. If that's the bar, past the existent harvest of models isn't clearing it.
There is 1 existent methodological statement here. ARC's study says a Duke-built customized harness pushed Claude Opus 4.6 from 0.25% to 97.1% connected a azygous situation variant called TR87. That does not mean Claude scored 97.1% connected ARC-AGI-3 overall; its authoritative benchmark people remained 0.25%, but the displacement is inactive worthy noting.
The authoritative benchmark feeds agents JSON code, not visuals. That's either a methodological flaw oregon a objection that today's models are amended astatine processing human-friendly accusation than earthy structured data. Chollet's instauration has acknowledged the debate, but isn't changing the format.
“Frame contented cognition and API format are not limiting factors for frontier exemplary show connected ARC-AGI-3,” the insubstantial reads. In different words, they look to cull the thought that models neglect due to the fact that they “can’t see” the tasks properly, arguing alternatively that cognition is already sufficient—and the existent spread lies successful reasoning and generalization.
The AGI world cheque arrived during a week erstwhile the hype instrumentality was moving astatine afloat speed. Besides Huang's comment, Arm named its caller data halfway chip the "AGI CPU." OpenAI's Sam Altman has said they've "basically built AGI," and Microsoft is already selling a laboratory focused connected gathering ASI: An improvement of what comes aft AGI is achieved. The word is being stretched until it means immoderate is commercially convenient, it appears.
Chollet's presumption is simpler. If a mean quality with nary instructions tin bash it, and your strategy can't, past you don't person AGI—you person a precise costly autocomplete that needs a batch of help.
ARC Prize 2026 is offering $2 cardinal crossed 3 contention tracks, each hosted connected Kaggle. Every winning solution indispensable beryllium open-sourced. The timepiece is running, and close now, the machines aren't adjacent close.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·