
.png) 3 weeks ago
14
3 weeks ago
14
In brief
- Hy3 preview is simply a 295 cardinal parameter Mixture-of-Experts exemplary with lone 21 cardinal progressive parameters, making it cheaper to tally than astir rivals of akin capability.
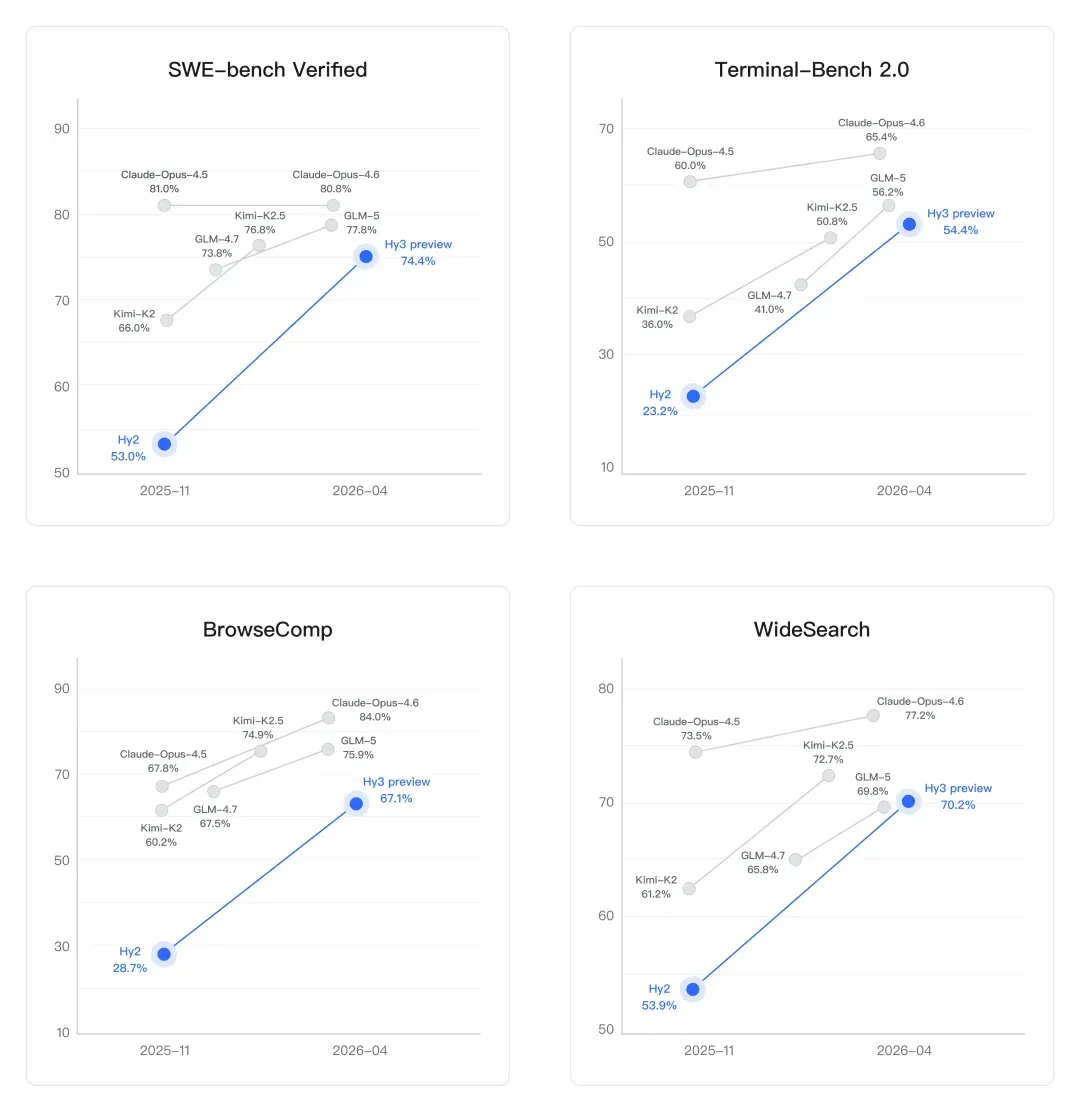
- On SWE-bench Verified—a coding benchmark investigating existent GitHub bug fixes—it jumped from 53% (Hy2) to 74.4%, a 40% betterment implicit the erstwhile generation.
- The exemplary is already unrecorded crossed Tencent's app ecosystem including Yuanbao, QQ, and Tencent Docs, with API entree connected Tencent Cloud starting astatine astir $0.18 per cardinal input tokens.
Tencent softly dropped its astir susceptible AI exemplary yet connected Thursday, and the benchmark numbers are hard to ignore. Hy3 preview, the company's archetypal exemplary aft a afloat infrastructure rebuild, went open-source contiguous crossed GitHub, Hugging Face, and ModelScope.
It’s besides disposable connected Tencent Cloud’s authoritative website, nether a paid plan.
My3 packs 295 cardinal full parameters (a measurement of a model’s imaginable breadth of knowledge) but lone 21 cardinal progressive astatine immoderate fixed time. That's the quality of a Mixture-of-Experts architecture—the exemplary routes each query to a specialized subset of its "expert" sub-networks alternatively of moving everything astatine once. Less compute, little cost, astir akin output quality. It besides supports up to 256,000 tokens of context, which is capable to swallow a full-length caller successful a azygous prompt.
The exemplary was built to equilibrium 3 things Tencent says it stopped sacrificing for each other: capableness breadth, honorable evaluation, and cost-efficiency. Their erstwhile flagship, Hy2, had implicit 400 cardinal parameters. Tencent explicitly walked that back, arguing 295 cardinal is the optimal saccharine spot wherever reasoning afloat matures but the outgo of adding much parameters stops paying off.
This besides doesn’t mean the exemplary is worse. Models with amended grooming and little parameters outperform bigger generalist ones rather frequently.
On coding, the betterment is dramatic. SWE-bench Verified is simply a benchmark that tests whether a exemplary tin really hole existent bugs from GitHub repositories—not artifact problems, but accumulation code. Hy2 scored 53.0%. Hy3 preview scores 74.4%. That's a 40% leap successful 1 generation, landing it successful scope of Claude Opus 4.6 (80.8%) and supra GLM-5 (77.8%) and Kimi-K2.5 (76.8%). Terminal-Bench 2.0, which measures autonomous task execution successful a existent command-line environment, went from 23.2% to 54.4%—also a monolithic leap.
The model, however, tin beryllium a precise absorbing prime for radical gathering with agents. Agents person a precise analyzable acceptable of instructions that impact memories, skills, and instrumentality calls. They usually miss something, which tin ruin a workflow oregon nutrient mediocre results. That’s wherefore agentic capabilities are becoming much and much important for AI developers arsenic this country becomes the astir hyped happening successful the industry. It’s besides wherefore the exemplary was instantly made available connected Openclaw.
Search and browsing agents—where models indispensable retrieve, filter, and synthesize accusation from the unfastened web without quality guidance—also improved sharply. On BrowseComp, a benchmark tracking analyzable web probe tasks, Hy3 preview reached 67.1% (up from Hy2's 28.7%). On WideSearch, it deed 70.2%, outperforming GLM-5 and Kimi-K2.5 but trailing Claude Opus 4.6's 77.2%.
In reasoning, the exemplary topped each Chinese rival connected Tsinghua University's mathematics PhD qualifying exam (Spring 2026), scoring 88.4 connected the mean of 3 runs avg@3. That's a real-world exam, not a curated dataset—the benignant of valuation Tencent says it's prioritizing to debar benchmark gaming. The exemplary besides scored 87.8 connected CHSBO 2025 (China's nationalist precocious schoolhouse biology olympiad), highest among Chinese models successful that category.
Hy3 preview started grooming successful precocious January 2026 and launched Thursday—under 3 months from acold commencement to open-source release. Unusually accelerated for a frontier-class model. Tencent attributes it to a February infrastructure overhaul led by Yao Shunyu, its main AI scientist, who pushed a afloat rebuild of the pretraining and reinforcement learning stack.
This is simply a precise antithetic attack from what Chinese AI labs were doing a twelvemonth ago, erstwhile DeepSeek's R1 shocked the industry with its cost-efficiency.
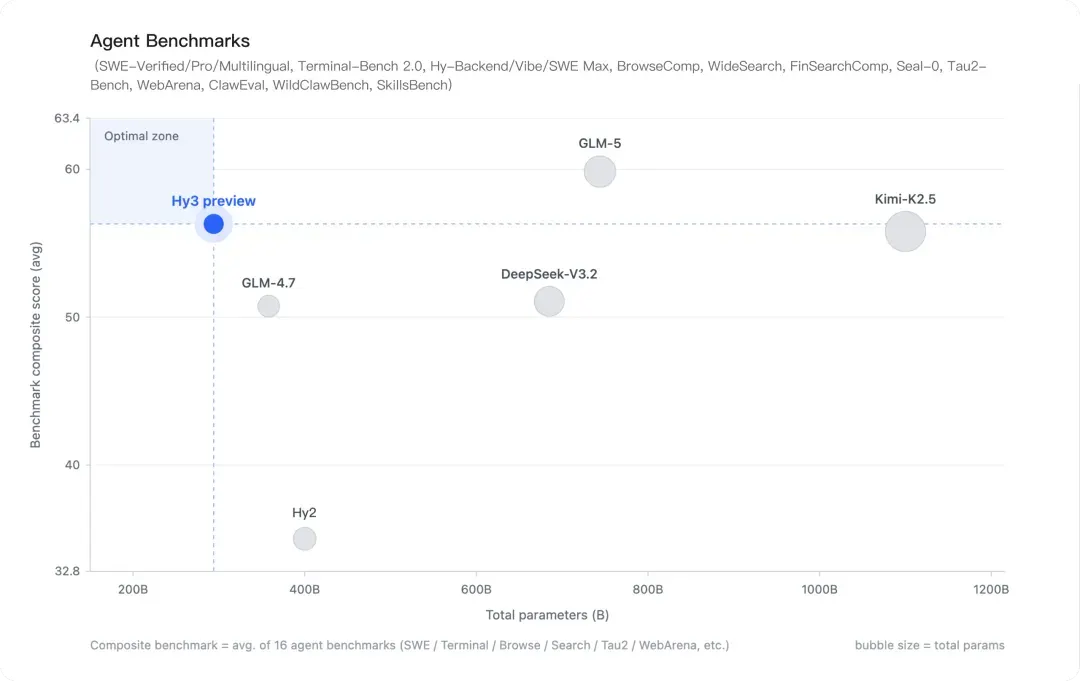
Hy3 inactive trails OpenAI and Google DeepMind's flagships, but by the size-to-performance ratio, Hy3 preview is hard to dismiss: the cause benchmark composite shows it successful the "optimal zone" with ~295 cardinal parameters, up of DeepSeek-V3.2 (600 billion+) and matching Kimi-K2.5 (over 1 trillion parameters) astatine a fraction of the compute cost.
Hunyuan models person already been deployed crossed Yuanbao, CodeBuddy, WorkBuddy, QQ, and Tencent Docs. On CodeBuddy and WorkBuddy, first-token latency dropped 54%, end-to-end procreation clip fell 47%, and the exemplary successfully ran cause workflows arsenic agelong arsenic 495 steps. Tencent Cloud is offering API entree astatine astir $0.18 per cardinal input tokens and $0.59 per cardinal output tokens, with idiosyncratic Token Plan packages starting astatine astir $4.10 per month.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·