
.png) 1 week ago
14
1 week ago
14
In brief
- CAISI's valuation ranked DeepSeek V4 Pro 8 months down the U.S. frontier, utilizing an IRT-based scoring strategy crossed 9 benchmarks including 2 private, unverifiable datasets.
- The outgo examination excluded each U.S. models deemed excessively costly oregon excessively weak—leaving lone GPT-5.4 mini, against which DeepSeek was inactive cheaper connected 5 retired of 7 benchmarks.
- Stanford's 2026 AI Index recovered the U.S.-China show spread connected nationalist leaderboards had collapsed to 2.7%.
A U.S. authorities institute published its verdict connected China's astir almighty AI: 8 months behind, and the much clip passes, the wider the spread gets. The net work the methodology and started asking questions.
CAISI—the Center for AI Standards and Innovation, a portion wrong NIST—released its evaluation of DeepSeek V4 Pro connected May 1. The conclusion: DeepSeek's open-weight flagship "lags down the frontier by astir 8 months."
CAISI besides calls it the astir susceptible Chinese AI exemplary it has evaluated to date.
The scoring system
CAISI doesn't mean benchmark scores similar astir evaluators do. Instead, it applies Item Response Theory—a statistical method from standardized testing—to estimation each model's latent capableness by tracking which problems it solves and which it doesn't, crossed 9 benchmarks successful 5 domains: cybersecurity, bundle engineering, earthy sciences, abstract reasoning, and math.
The IRT-estimated Elo scores: GPT-5.5 astatine 1,260 points, Anthropic's Claude Opus 4.6 astatine 999. DeepSeek V4 Pro scores astir 800 (±28), which is precise adjacent to GPT-5.4 mini astatine 749. In CAISI's system, DeepSeek sits person to the aged procreation of GPT mini than to Opus.
The points strategy successful benchmarks people models the mode standardized tests people students—not by earthy percent correct, but by weighting which problems they lick and which they miss, producing a points estimation that lone means thing comparative to different models successful the aforesaid evaluation. The much points, the amended the exemplary is successful wide terms, with the champion model’s people becoming the notation constituent to spot however susceptible a exemplary is.
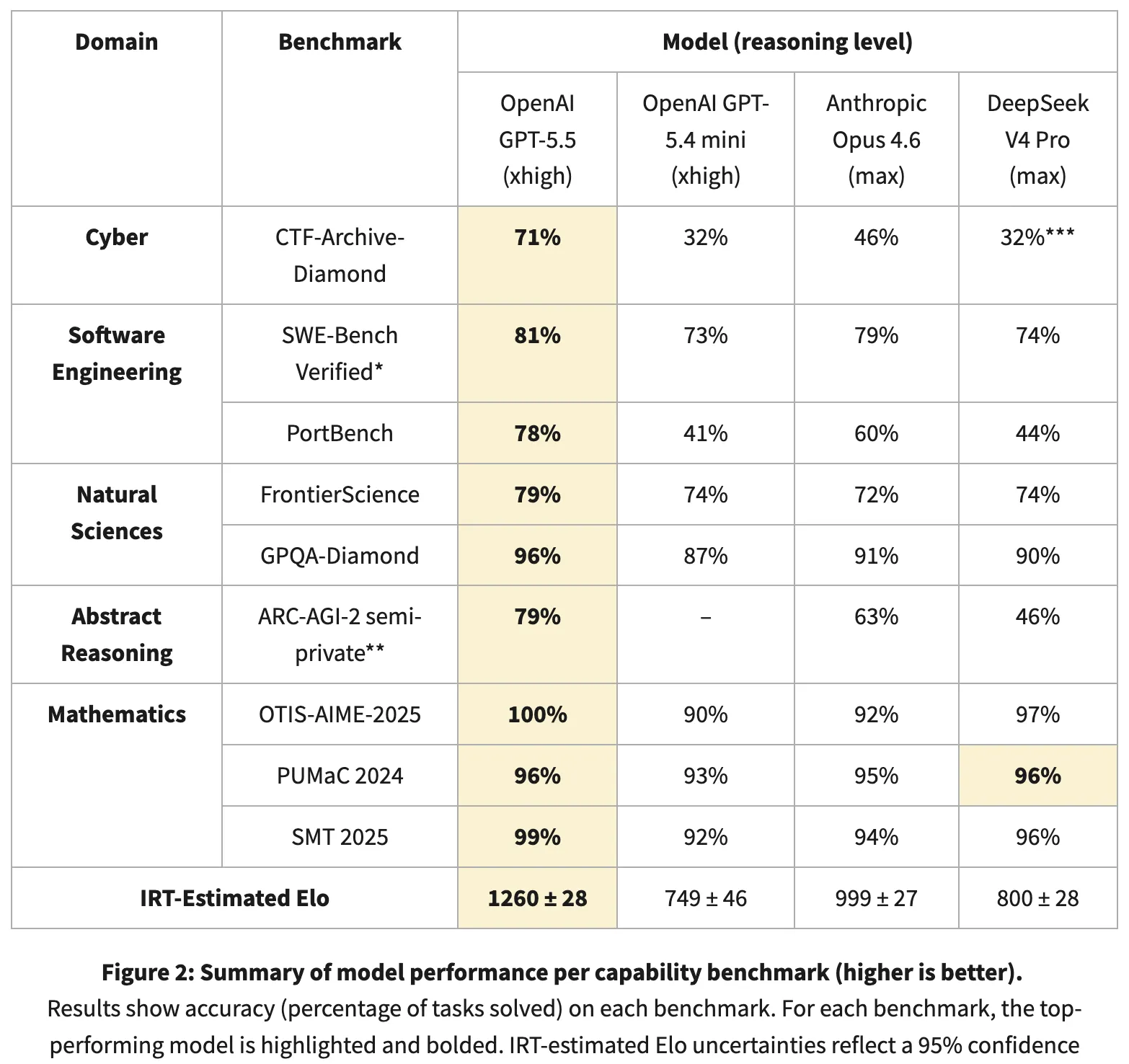
It’s intolerable to reproduce CAISI’s results due to the fact that 2 of the 9 benchmarks are non-public, and successful those 2 benchmarks is wherever the spread is widest. For example, GPT-5.5 scored 71% connected CTF-Archive-Diamond, 1 of CAISI’s cybersecurity tests with DeepSeek registering astir 32%.
On nationalist benchmarks, the representation shifts. GPQA-Diamond—PhD-level subject reasoning, scored arsenic percent correct—placed DeepSeek astatine 90%, 1 constituent down Opus 4.6's 91%. Math olympiad benchmarks (OTIS-AIME-2025, PUMaC 2024, SMT 2025) enactment DeepSeek astatine 97%, 96%, and 96%. On SWE-Bench Verified—real GitHub bug fixes, scored arsenic percent resolved—DeepSeek scored 74% to GPT-5.5's 81%. DeepSeek's ain method study claims V4 Pro matches Opus 4.6 and GPT-5.4.
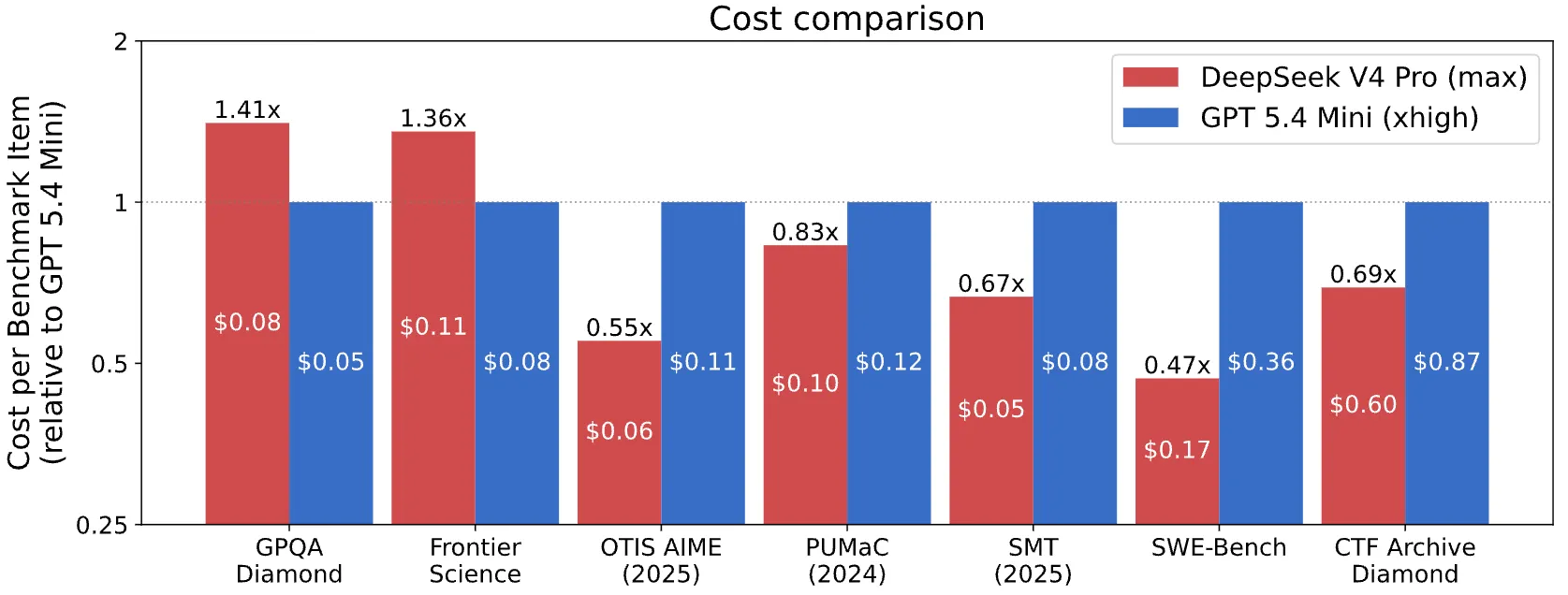
For outgo comparison, CAISI filtered retired immoderate U.S, exemplary that performed importantly worse oregon outgo importantly much per token than DeepSeek. Only 1 exemplary cleared the bar: GPT-5.4 mini. That's the full U.S. frontier, filtered to a azygous entry.
DeepSeek came retired cheaper connected 5 of 7 benchmarks adjacent beating OpenAI’s tiniest and slightest susceptible AI model.
The counterargument: Is the spread bigger oregon smaller?
Criticizing CAISI's methodology doesn't afloat vindicate DeepSeek. The AI developer nether the pseudonym Ex0bit pushed backmost directly: "There's nary 'gap', and nary one's 8 months behind. We've been trolled connected each closed U.S driblet and flexed connected with unfastened weights."
The Artificial Analysis Intelligence Index v4.0—a standing strategy tracking frontier exemplary quality crossed 10 evaluations—shows OpenAI adjacent 60 points and DeepSeek successful the debased 50s arsenic of May 2026, compressed acold tighter than a twelvemonth ago.
Based connected standardized benchmarks, their methodology shows the spread is really getting smaller.
When DeepSeek archetypal emerged successful January 2025, the question was whether China had already caught up. U.S. labs scrambled to respond. Stanford's 2026 AI Index—released April 13—reports the Arena leaderboard spread betwixt Claude Opus 4.6 and China's Dola-Seed-2.0 Preview is shrinking, separated present by lone 2.7%.
CAISI plans to merchandise a fuller IRT methodology constitute up successful the adjacent future.
Daily Debrief Newsletter
Start each time with the apical quality stories close now, positive archetypal features, a podcast, videos and more.







 English (US) ·
English (US) ·